


🔴 7 about... l'effet Google et le RAG

L'effet Google
1. L'effet Google (ou amnésie numérique) est notre tendance à ne pas faire l’effort de mémoriser des informations si elles sont facilement accessibles en ligne (ou sur nos téléphones et ordinateurs). Quelques exemples : le numéro de téléphone de nos proches, la définition d’un mot, les informations essentielles d’un pays sur lequel nous travaillons…
2. Lorsque nous ne faisons que consulter ces informations, nous ne les intégrons pas durablement et ne pourrons donc pas les réutiliser spontanément quand nous aurons à évaluer une situation ou résoudre un problème.
3. Une première étude a révélé ce phénomène en 2011, étude réalisée par les psychologues américains Betsy Sparrow (Columbia University), Daniel M Wegner (Harvard University) et Jenny Liu : Google Effects on Memory: Cognitive Consequences of Having Information at Our Fingertips. Pour faire bref, les expériences menées montraient notamment que :
nous oublions plus facilement une information si nous savons qu’elle est stockée à un “endroit” facilement accessible ;
nous nous souvenons davantage du nom du “lieu” de stockage, même complexe, que de l’information elle-même.
4. En considérant Internet, nos ordinateurs et nos téléphones comme des mémoires externes auxquelles nous pouvons accéder le besoin venant, nous accentuons une dépendance à l'égard de la technologie, qui pourrait non seulement nuire à notre intelligence mais aussi à notre bien-être, à notre capacité d’attention, voire à nos aptitudes sociales (se souvenir du nom exact et de la fonction d’une personne sans aller faire un tour sur Linked-In par exemple).
5. Le même phénomène peut se produire avec la photographie. Sans surprise, nous nous souvenons mieux de quelque chose lorsque nous l’observons que lorsque nous le photographons : nom, forme, détails… ce qui laisse perplexe si l’on pense à certains touristes qui photographient à tout va, sans même se donner la peine de regarder.
6. Toutefois, on peut aussi considérer que ces “stockages externes” fonctionnent comme des livres et des bibliothèques. En effet, lorsque nous refermons un livre, nous n’avons pas mémorisé l’ensemble des informations que nous venons de lire. En revanche, nous savons où se trouve ce livre, et donc ces informations, dans notre bibliothèque.
7. Le même phénomène se produit dans une équipe où les informations réparties entre ses membres, peuvent être réunies et combinées en fonction de la question à résoudre. L’effet Google serait donc une forme de mémoire transactive (collective).
La leçon à retenir
Avec ChatGPT et autres AI disponibles, le risque est que nous ne nous souvenions même pas de ce que nous sommes censés avoir écrit ou créé. Hum, ça va devenir compliqué…
Pour aller plus loin
L’article originel : Betsy Sparrow - Information at Our Fingertips Google Effects on Memory: Cognitive Consequences of Having

Le RAG
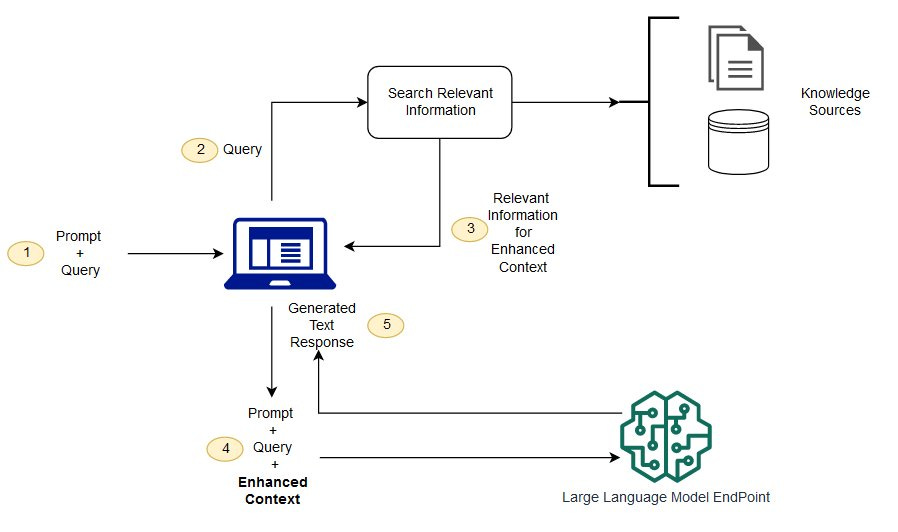
1. Le RAG (Retrevial Augmented Generation ou Génération augmentée par récupération) est une technique récente d’amélioration des grands modèles de langage (LLM) tels que ChatGPT d’Open AI, Gemini de Google ou encore le français Mistral. L’enjeu ici n’est autre que de permettre à l’humain de reprendre le contrôle sur les outils d’IA tout en améliorant leurs performances.
2. Selon une étude de la Harvard Business School (septembre 2023), les tâches réalisées par les outils d’IA générative comportent 19 % d’erreurs en plus que les mêmes tâches effectuées par un humain. Trois raisons principales expliquent ce taux d’erreur plus élevé :
Les sources utilisées pour générer les réponses ne sont pas identifiées et vérifiées.
Ces sources ne sont pas à jour.
Le “défaut” finalement très humain, de ne pas “avouer” qu’on ne sait pas, conduit l’outil à donner coûte que coûte une réponse, même fausse (les fameuses hallucinations).
Le RAG propose de combler ces failles.
3. Première étape : constituer et utiliser des bases de données ne contenant que des informations fiables, à jour et exactes, provenant de sources de confiance identifiées (articles, publications, sites web de référence, données internes à une organisation…). Prenons un exemple : pour disposer d’informations fiables et actualisées dans le domaine du sport, il faudra sélectionner comme sources de confiance, les média spécialisés, les clubs, les associations, les fédérations… ou les bases de données que vous aurez vous-même constituées.
4. Seconde étape : modifier les instructions données à l’outil d’IA, de sorte qu’il suive la procédure suivante (on se permet de tutoyer la machine) :
Va extraire des données à partir de mes sources de confiance.
Vérifie la pertinence de ces données par rapport au prompt (question posée).
Génère des réponses en citant tes sources, ce qui permettra d’en vérifier la fiabilité.
Et enfin (et surtout !), si tu ne sais pas, pas de problème ! Tu le dis et tu ne réponds pas n’importe quoi.
5. Plusieurs domaines se prêtent particulièrement bien à l’usage des RAG :
Les services d’assistance clients : améliorer l’efficacité des assistants virtuels.
La publication de contenus : augmenter la capacité de production d’articles, de catalogues…
La rédaction d’études : améliorer la qualité des rapports en disposant de données fiables et à jour.
6. Autres avantages du RAG :
Il permet aux outils d’IA générative d’apprendre mieux et plus vite qu’avec les modèles traditionnels s’appuyant sur la correction des données auto-générées.
La mise à jour des données se fait plus rapidement puisque les sources de confiance utilisées sont elles-mêmes mises à jour.
Les risques de fuite de données confidentielles sont moindres puisque les sources sélectionnées restent privées.
7. Le concept de RAG est de plus en plus largement adopté par les entreprises et les particuliers, car, les outils d’IA générative étant accessibles à tous, la différence se fera sur la façon de s’en servir et sur la qualité des informations que nous fournissons à la “machine”.
La leçon à tirer
Nous revenons finalement à des problématiques humaines bien connues : l’identification et la fiabilité des sources. On se croirait en première année d’université…
Pour aller plus loin
Le texte original, publié sur Arvix : Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, Facebook AI Research, University College London, New York University
Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality - Harvard Business School